

Summary
Column CVs are visually appealing and are becoming widely used by candidates. We estimate that currently at least 15% of CV documents use a column layout. However, properly dealing with this layout is a surprisingly difficult computer vision problem. Since third party tools do not work well on CVs or are very slow, Textkernel already had a system in place to deal with column layout documents. We have greatly improved this system by applying various AI techniques. As a result, our handling of column CVs in PDF format has improved significantly, resulting in better extraction quality regardless of the document language.
Intro
The first step in an information extraction pipeline is to convert documents into raw text from which information can be extracted.
The system’s ability to perform well in this first step is crucial: any mistake will impact the performance of subsequent steps. Generating a well-rendered text representation for many different types of documents is a difficult problem to solve.
A simple method, that renders the text in a top-down, left to right order is usually sufficient for documents that have a standard layout.

However, CVs come in various layouts, which are easy for humans to understand, but can be challenging to a machine.
A common layout we find in CV documents is the usage of columns. Column CVs are visually appealing and widely used by candidates applying for a job. Candidates want to neatly organize the information in their CV and provide visual structure, for example by having a sidebar that contains their contact information.
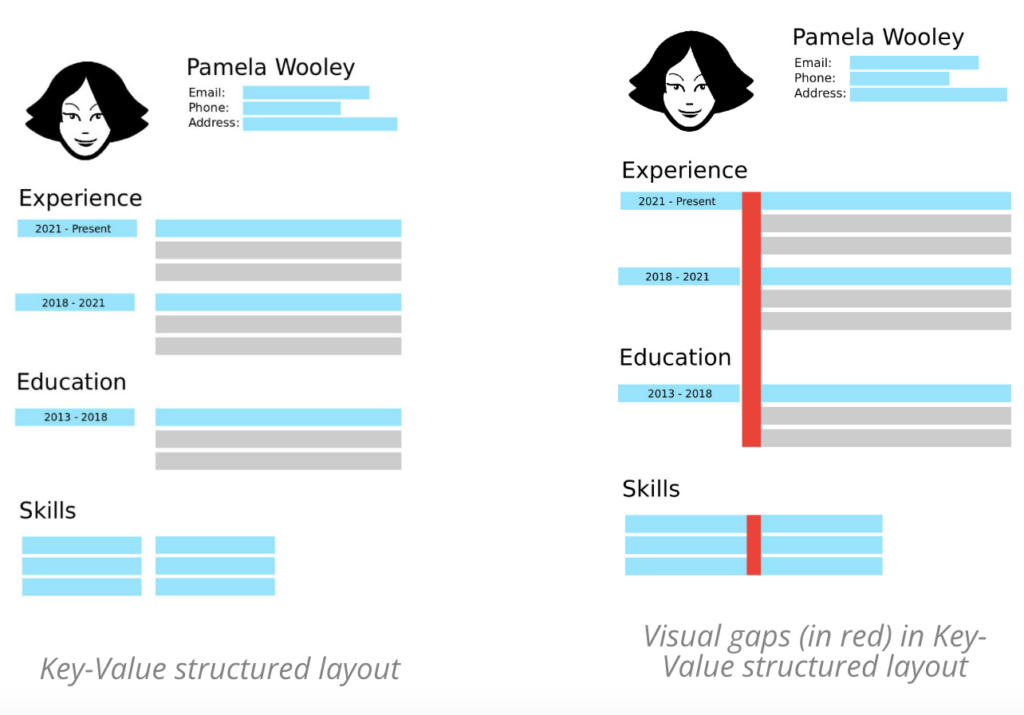
If a system were to use the basic left-to-right, top-down order rendering for this type of document, that would generate a rendering where the information from different sections of the CV is mixed together (see image aside).
Instead of reading the columns one after the other, the system would mix bits and pieces of each column together.

An imperfect text rendering can still be useful for certain tasks: searching for keywords is still possible, and humans can still easily read the document.
But when automated systems try to extract structured information from an imperfect rendering, problems compound very quickly: finding the correct information becomes incredibly challenging.
At Textkernel, we strive to offer the best parsing quality on the market, which means that the widespread use of column based layouts demands our full attention. Keep reading to follow us on our journey to create a system that can understand creative document layouts and see how we were able to leverage machine learning to bring our Extract! product to the next level.
Our Previous Approach
Our system was already able to handle several types of document layouts, being able to identify sections of a document that should be rendered independently.
The approach has 3 steps. In the first step, the text content of the PDF is scanned and visual gaps between them are identified (see below an example). In the second step, a rule-based system decides whether a visual gap is a column separator or not. As you can see in the example below, not all visual gaps are column separators and the left-to-right reading should not be interrupted for these gaps. Based on these predictions, in the third step the text will be rendered by separating all identified columns.

A naive approach that always renders the big visual gaps separately would have issues on several types of layouts, as an example a key-value structured layout would break the key from the value and separate it in its text representation, leading to incorrect extraction of fields.
Our system achieved good rendering for many cases but was still failing to predict certain column separators. By design the system was very precise when predicting that the visual gap is a column separator (i.e. precision of the positive class is very high), the rationale being that predicting a column separator when there is none (i.e. a false positive) is very costly: the rendered text will be wrong and as a result it would affect the parsing quality. In order to achieve this high precision, its coverage was more limited (i.e. precision of the positive class was favored over the recall of the positive class). In addition, the system is also very fast (tens of milliseconds), making it a quite efficient solution.
Improving such a system requires a model centric approach: we have to focus our efforts in changing the code. For example, increasing the coverage of supported cases is very difficult. When we encounter a new case, we need to implement a new rule for it, make sure it is compatible with the rest of the rule base and choose how the rules should be applied and combined. Complexity can grow very high with the more rules we add.
Ideally we would like our solution to be data centric, so we can improve its performance by collecting examples of how the system should perform, and focus our attention on curating and improving the example data. We would also like a solution that preserves our processing speed.
The first improvement trial
We analyzed several third party solutions that might help us improve our system, without going through all the difficulties of managing a rule-based system.
Most of these systems apply computer vision methods to extract text from an image representation of the document. These require computationally expensive algorithms and are therefore quite slow (i.e. seconds), and also difficult to manage for on-premise installations. We were also surprised to see that their performance was not much better than our previous rule-based approach. Therefore, we abandoned the third party track.
As we are focusing on improving our column handling, we don’t need to identify all the gaps in the text, only the larger vertical visual gaps should correspond to columns. With these simplified assumptions, we came up with a new method to detect the largest vertical visual gap from a histogram of the whitespace in the image representation of the document, as can be seen in the image below.
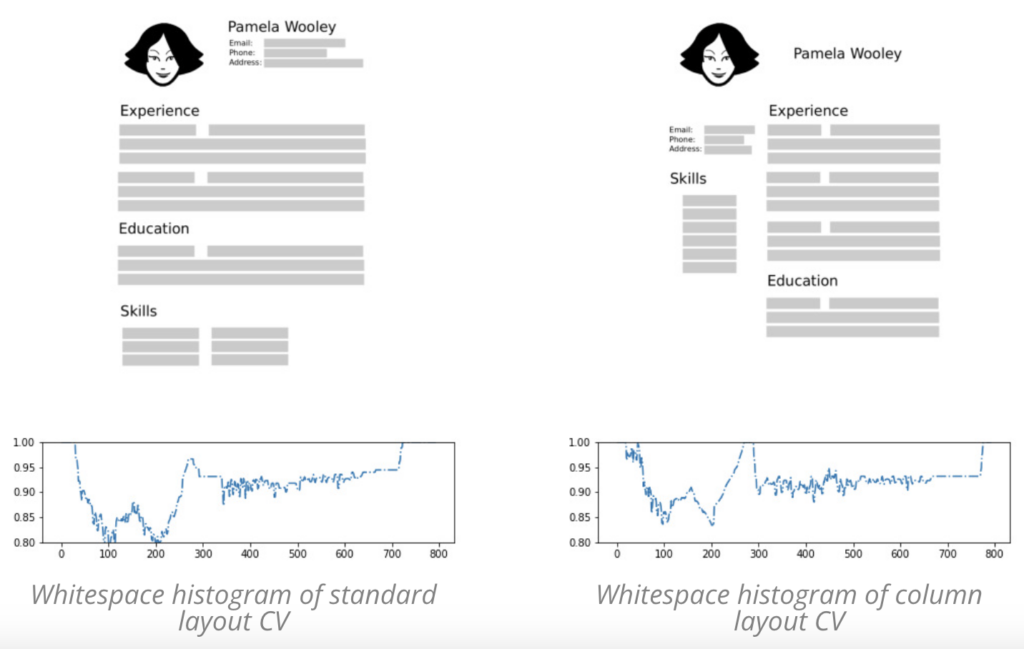
Looking at this representation, we can see a distinction between both types of layouts in terms of whitespace distribution, and we used this representation to train a neural network model for classifying between column layouts and regular layouts.
Note that this method does not fit all our requirements: we still don’t have the coordinates needed to separate the column content. In addition, we also noticed the processing speed will be an issue if we continue on this track.
Given the expected effort still to get this method to a usable state, we took a step back and went back to the drawing board.
Our New Approach
We already stated that in our ideal scenario we would be able to improve our system by feeding it good quality data. How can we move from our model centric approach into a data centric approach?
At the core of our solution we have a single type of decision: deciding if a visual gap is separating related or unrelated content (e.g. a column separator). This is a binary classification problem, for which we can train a machine learning model to replicate the decision.
By making use of our rule-based system we can generate our training data by converting our rules into features and our output decision as the label we want our new model to learn. By doing this we can begin to focus on improving the collection and curation of more training data, and easily retrain the model everytime we want to improve it, instead of adding more rules to our code base.
We have a new approach and we need to validate it. For that we follow the model development pipeline:
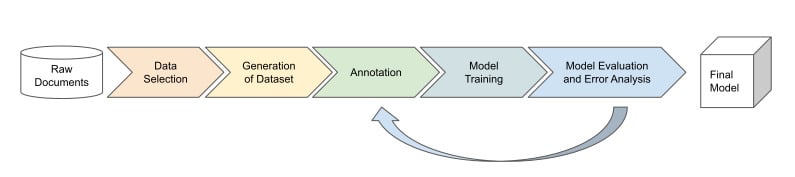
Data Selection
We start with selecting the data for training our machine learning model. Unlike a rule-based system that needs a few hundred examples to develop and test the rules, we will need several thousand examples to learn our model.
We started with problematic documents that our customers kindly shared with us in their feedback. However, this set was quite small (about 200 documents). How can we find thousands more column CVs when they only account for about 10-15% of documents? Luckily, from our initial attempt we have a neural network based column classifier. Although not sufficient for replacing our old rule-based system, it’s a great method to mine documents with a column layout. Even if this classifier is not 100% accurate, it is still better than randomly selecting documents (which will have an accuracy of 10-15%). In addition, we also collect a random sample of documents to make sure our method works well across all layouts (i.e. ensure we do not break rendering of correctly working document layouts).
Generation of the Dataset
To generate our dataset we process our document sets through our existing rendering pipeline. For each visual gap, the target label is initially set to the decision made by our rule-based system. We bootstrapped the features by using the variables and rules computed in this decision. In addition, we added several new features that quantify better some of the properties of column layouts.
Manual Annotation
In the previous step we generated a pseudo-labeled dataset: the labels originate from our existing system and are not verified by a human. To ensure that our machine learning model will not simply learn to reproduce the mistakes of the rule-based system, we also manually annotated a small sample of column CVs. Since this is a time consuming task, having potential column CVs as identified by our neural network based column classifier helped to speed up our annotation process.
Model Training
We can now train a machine learning model to mimic our ruled-based system decisions. We started our experiments with the decision tree algorithm. This is a simple algorithm to apply to our dataset and very effective, offering good classification performance while very fast to apply, a key characteristic we wanted in our approach.
However, decision trees have several problems: they are prone to overfitting and suffer from bias and variance errors. This results in unreliable predictions on new data. This can be improved by combining several decision tree models. Combining the models will result in better prediction performance in previously unseen data.
There are several ways to achieve this, the more popular methods being bagging, where several models are trained in parallel on subsets of the data: an example of such method is the random forest. Another ensemble method is boosting, where models are trained sequentially, each model being trained to correct the mistakes of the previous one: an example of such method is the gradient boosting algorithm.
After testing a few options we settled on the boosting approach using a gradient boosting method.
Efficient Label Correction
Our new model was mostly trained to reproduce the decisions of our rule-based system because most of its training data comes from pseudo-labeled examples. The limited human annotations also makes it difficult to do error analysis and identify which cases the new model is misbehaving.
Even so, the added small sample of manually annotated data for column CV documents can already shift the decision in informative ways. As a result, the discrepancy between the predictions of the new method and the rule-based system can be analyzed manually and corrected. We call this approach delta annotation. This is an effective process of labeling only the data that will push the model into performing better.
At Textkernel we are always looking for ways to deliver the best quality parsing. Having quality data is essential for what we do, so of course, we already have implemented great solutions for this using tools such as Prodigy to facilitate rapid iteration over our data.
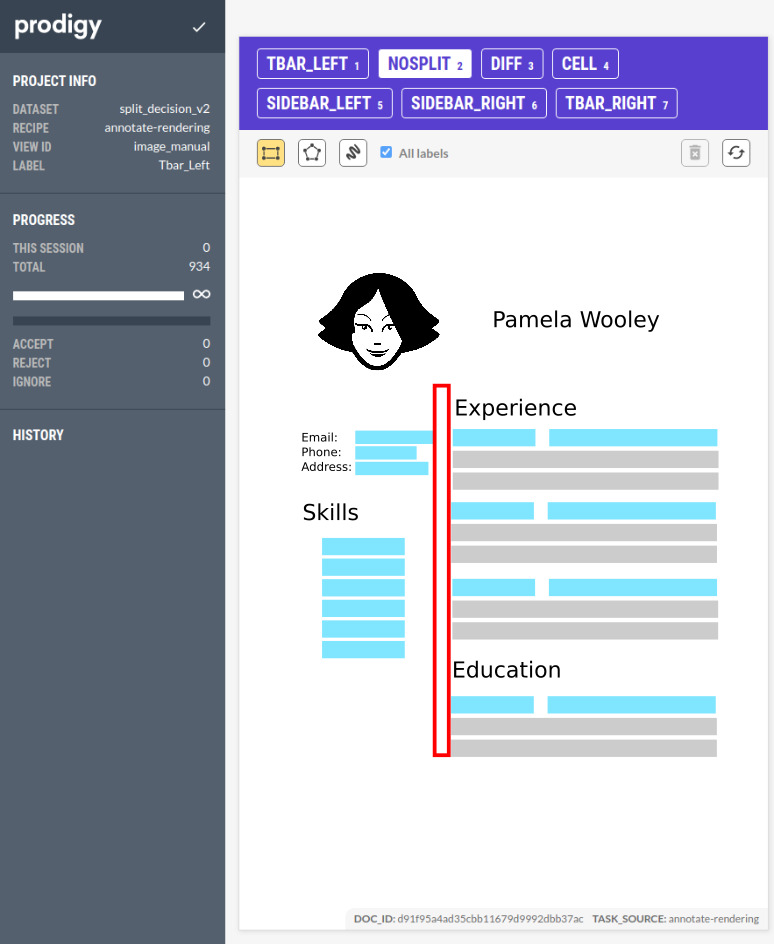
WIth this partially corrected dataset, we can retrain our model and we can keep iterating and improving our dataset by doing delta annotation between the latest model and the older ones. In our case, two iterations was enough to saturate the differences and reach a good performance at the visual gap level.
This enables us to follow a data centric approach, we can focus on systematically improving our data in order to improve the performance of our model.
Evaluation
We have a new approach that is more flexible than before, but we still have a big challenge. How can we be sure that better decisions at the visual gap level translate in an overall improvement in rendering at the document level (recall that a document can have multiple visual gaps). Even more important, does this translate into extraction quality improvements? If we want to be confident in our solution, we need to evaluate our system at multiple levels.
Firstly, we did a model evaluation to know if we are better at making decisions at the visual gap level. For this, we can simply use our blind test set and compare the performance of our new model with the old model. On more than 600 visual gaps, our new model makes the right decision in 91% of the cases as opposed to only 82% for our old rule-base system. However, visual gaps are not all equally important and some matter more than others: in our case, the visual gaps corresponding to columns are the most important to get right. For this important subset, we see a performance increase from 60% to 82%. In other words, we have more than cut in half the errors we used to make!
Secondly, we looked to see if the improvement in visual gap classification translates into better rendering (recall that in a document there might be multiple visual gaps). In other words, are we doing a better job of not mixing sections in column CVs? However, since multiple renderings can be correct, it is hard to annotate a single “correct” rendering (which would have allowed us to automatically compute rendering performance). Therefore, we had to do a subjective evaluation of the rendering. Using our trustworthy Prodigy tool, we displayed side-by-side the renderings of the new and the old system to our annotators (without them knowing which side is which). The annotators evaluated if the text is now better separated, worse, or roughly the same as before. The results on a set of about 700 CVs are really good: well rendered CVs increased from 62% to 90%.
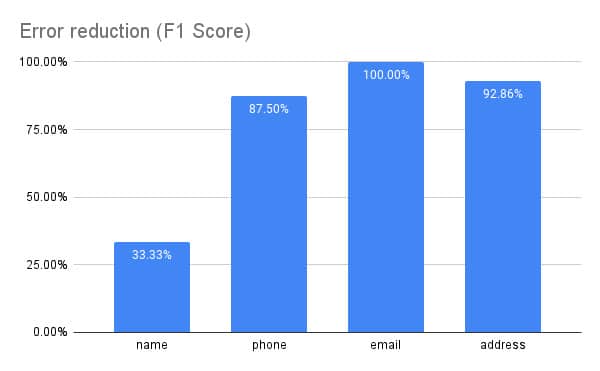
Finally, we looked to see if better rendering translates in better parsing. We knew that in column CVs where the old system was failing, our parser would sometimes extract less information, in particular contact information like name, phones and address. Thus, the least labor intensive way is to simply check if the fill rates are increasing. On more than 12000 random CVs, we see that the contact information fill rates are increasing by 4% to 10% absolute. But more does not necessarily mean better! Thus, we also invested in evaluating more than 1000 differences between our parser using the old system and our parser using the new system. The results in the figure below show the percentage of errors our new system has fixed. This is our final confirmation that we now have in our hands a better parser! Great job team!
Conclusions
Our extraction quality on column CVs is now better than ever. By leveraging machine learning to replace our rule-based system we can now correctly parse an even wider range of CV layouts.
Our main takeaways from this project are:
– It is important to choose the right approach. For certain problems, more complex approaches or ML models require a lot of time investment to get right and still have speed issues.
– Experimenting with several approaches, even if abandoned, still brings value. These systems can be complimentary in parts of the pipeline (e.g. for efficient data selection).
– With the right data and ML methods, a rule-base system can be bootstrapped into an ML system with significantly better generalization capabilities.
– Further improvements to the system can be done by improving the training data instead of the complex task of managing the rules.
– It is important to look at the global picture especially for systems with downstream tasks.
– Local improvements need to be evaluated globally to validate their effectiveness
Don’t miss out on the great candidates that make use of these layouts!
About Textkernel
Textkernel is a global leader in providing cutting-edge artificial intelligence technology solutions to over 2,500 corporate and staffing organisations worldwide. Our expertise lies in delivering industry-leading multilingual parsing, semantic search and match, and labour market intelligence solutions to companies across multiple sectors.
With over two decades of industry experience, we are at the forefront of AI innovation and use our knowledge and expertise to create world-class technology solutions for our customers. At Textkernel, we are dedicated to translating the latest AI thinking into practical, effective tools that help our clients streamline their recruitment processes, improve candidate experiences, and achieve better business outcomes.
Media Contact: Chloe Shoobridge | shoobridge@textkernel.com

