

Pour Jobs Data, la base de données en temps réel de Textkernel pour l’analyse du marché du travail, nous parcourons le web à la recherche d’offres d’emploi en ligne. Bien entendu, la garantie de la qualité de cette base de données soulève de nombreux défis techniques. L’un d’entre eux est la détection des doublons d’offres d’emploi. Dans cet article de blog, nous expliquons comment Textkernel résout ce problème.

L’offre d’emploi en ligne moyenne comporte de nombreux doublons
Lorsque l’on travaille avec de gros volumes de données web, on est tôt ou tard confronté au problème du contenu dupliqué. De nombreuses pages web ne sont pas uniques : un article de Google suggère qu’environ 30 % des pages web sont des quasi-doublons.
Dans Jobs Data, où nous analysons les annonces d’emploi en ligne dans huit pays, ce problème est encore plus important : nous avons découvert qu’une annonce d’emploi moyenne est réaffichée 2 à 5 fois (selon le pays), ce qui fait que la fraction de doublons peut atteindre 50 à 80 %. Cela n’est pas surprenant : les entreprises diffusent leurs offres d’emploi le plus largement possible afin d’attirer davantage de bons candidats : sur les sites des entreprises, sur des sites d’emploi généraux et spécialisés, par l’intermédiaire d’agences de recrutement, etc. L’identification et le regroupement des annonces en double constituent donc une étape essentielle de notre traitement des données.
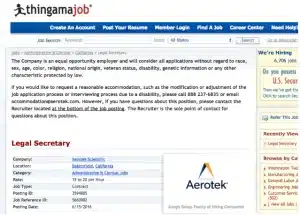
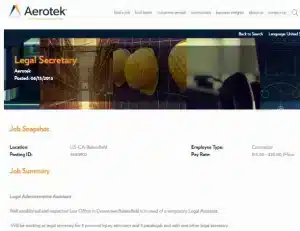
Les offres d’emploi quasiment identiques sont rarement identiques : lorsqu’une annonce est publiée sur un autre site, le texte est souvent restructuré, raccourci ou étendu et les métadonnées sont souvent modifiées pour correspondre au modèle de données du site. Prenons l’exemple de deux annonces pour le même poste, présentées ci-dessous :
Similitude textuelle
Les méthodes efficaces de recherche de pages web similaires sont presque aussi anciennes que le web lui-même : un article fondateur, Syntactic clustering of the web, de A. Broder et al. a été publié en 1997. Dans Jobs Data, nous utilisons une approche classique basée sur le shingling et les permutations minimales.
Comme nous le montrons ci-dessous, une implémentation relativement simple peut facilement traiter des dizaines de millions de documents. Pour les ensembles de données comportant des milliards de documents, une implémentation plus sophistiquée et/ou une méthode différente est nécessaire : voir l’article de blog Near-Duplicate Detection pour un aperçu et l’article Detecting Near-Duplicates for Web Crawling pour plus de détails. Avec le shingling, nous convertissons chaque document texte en un ensemble de toutes les séquences (shingles) de mots consécutifs tels qu’ils apparaissent dans le document.
Par exemple, si nous considérons des séquences de 6 mots pour le texte “Un cabinet d’avocats bien établi et respecté du centre-ville de Bakersfield a besoin d’un assistant juridique temporaire …”, les shingles comprendront:
– “Cabinet d’avocats bien établi et respecté”
– “Cabinet d’avocats établi et respecté du centre-ville”
– “et respecté du centre-ville” etc.
Nous pouvons mesurer la similarité textuelle entre deux documents comme le chevauchement entre leurs ensembles de shingles. Pour notre exemple d’annonces “secrétaire juridique”, les deux documents se partagent 179 des 484 bardeaux totaux, ce qui nous donne une similarité de 37 %. Ce chiffre peut sembler faible, étant donné que les descriptions de poste sont presque identiques : il est principalement dû au formatage différent des métadonnées (lieu, nom de l’entreprise, téléphone) et à l’absence de texte sur l’égalité des chances en matière d’emploi. Il est clair que pour les offres d’emploi, l’utilisation d’un simple seuil de similarité pour décider si deux annonces sont des doublons ne serait pas suffisante.
Recherche efficace de documents similaires
Pour éviter de stocker et de comparer des centaines de bardeaux pour chaque document, nous appliquons un système de hachage sensible à la localité, comme suit. Nous commençons par faire correspondre chaque bardeau d’un document à un entier de 64 bits à l’aide d’une bonne fonction de hachage. Appelons ces entiers des hachages de bardeaux. Nous prenons une permutation aléatoire fixe d’entiers, l’appliquons à tous les hachages de shingle du document et prenons la plus petite valeur – c’est la première valeur que nous stockerons. Nous répétons cette opération M fois avec différentes permutations aléatoires fixes, afin d’obtenir une liste de M nombres entiers : nous appelons cela l’esquisse du document. Il s’avère que pour estimer la similarité de deux documents, il suffit de compter le nombre d’entiers correspondants dans leurs esquisses. Cela signifie qu’il suffit de stocker M entiers pour chaque document. En choisissant une valeur appropriée pour M, nous pouvons trouver un bon compromis entre la précision de l’estimation et les exigences en matière de stockage.
Comment stocker les esquisses de documents pour une consultation rapide des documents similaires ? Nous utilisons une technique courante : un index inversé. Nous calculons les esquisses de tous les documents de notre ensemble de données et, pour chaque entier observé, nous stockons une liste de documents dont les esquisses contiennent cet entier. Pour trouver des documents similaires à une nouvelle entrée, il suffit de fusionner les listes de documents pour les M entiers de son esquisse. La gestion efficace de ces index en termes de temps et de mémoire est un domaine dans lequel Elasticsearch excelle, et nous l’utilisons donc pour indexer nos esquisses et extraire d’éventuels documents presque identiques. Nous mettons l’index à jour en permanence au fur et à mesure que de nouveaux documents sont analysés dans Jobs Data.
Spécificités de la déduplication des annonces d’emploi
Comme je l’ai indiqué plus haut, nous utilisons le shingling, le min-wise permutation hashing et l’indexation inversée pour trouver des offres d’emploi textuellement similaires à un nouveau document d’entrée. Pour la détection générale des quasi-doublons, c’est souvent tout ce dont on a besoin : un simple seuil de similarité textuelle entre le document d’entrée et les candidats suffit pour décider si le document d’entrée est un doublon. Pour les offres d’emploi, une telle approche basée sur un seuil n’est pas suffisante : comme nous l’avons vu dans notre exemple, les vrais doublons peuvent avoir une similarité aussi faible que 37 %. Dans Jobs Data, nous complétons la recherche basée sur le texte par quelques astuces supplémentaires: – Nous appliquons des techniques d’apprentissage automatique et basées sur des règles pour supprimer le contenu non pertinent (texte passe-partout, navigation, bannières, annonces, etc.) – Nous utilisons notre analyseur sémantique formé spécifiquement pour les annonces d’emploi afin d’identifier les sections de texte contenant la description du poste et les exigences du candidat (par opposition à la description générale de l’entreprise qui fait l’objet de l’annonce, qui est souvent répétée dans de nombreuses annonces d’emploi sans rapport avec l’entreprise) – Pour chaque nouvelle annonce d’emploi, nous utilisons le shingling tel que décrit ci-dessus pour trouver les candidats dont le texte se chevauche de manière substantielle. – Nous formons un classificateur pour prédire si une entrée donnée et un candidat récupéré sont effectivement des annonces du même poste. Le classificateur s’appuie sur le chevauchement de texte et la correspondance entre d’autres propriétés des offres d’emploi, telles qu’extraites par notre analyseur sémantique : nom de l’organisation, catégorie professionnelle, informations de contact, etc. Trouve-t-il tous les doublons ? Regroupe-t-il les messages qui ne sont pas des doublons ? Une réponse courte serait que le système est “assez bon, à 90 % environ”. Une réponse plus longue nécessiterait une discussion sur les nombreuses façons possibles d’évaluer un tel système – ce que je ferai dans un article ultérieur. Quelques liens utiles – xxhash : une bonne bibliothèque de hachage pour Python – Fonctions de hachage d’entiers : fonctions de hachage réversibles mixtes par Thomas Wang qui peuvent être utilisées pour construire des permutations pseudo-aléatoires.
