


Quelques années après que Google a annoncé qu’il permettait de rechercher des objets et non des chaînes de caractères, les graphes de connaissances et les ontologies ont pris de l’ampleur dans les principales organisations d’information du monde en tant que moyen d’intégrer, de partager et d’exploiter les données et les connaissances dont elles ont besoin pour rester compétitives. But exactly is a knowledge graph and what form and content does it have in the case of Textkernel? What approach is used to construct it in a scalable, time-effective way that keeps the quality high? And, most importantly, what benefits does it bring to the technology and, consequently, business and customers of Textkernel? Ce sont les questions clés auxquelles Panos Alexopoulos, chef de l’équipe Ontology Mining, tentera de répondre dans cet article de blog.Par Panos Alexopoulos
Présentation de l’ontologie de Textkernel
Data Scientist est une profession (très à la mode) et hadoop est une compétence que la plupart des data scientists doivent posséder. La macroéconomie et la microéconomie sont toutes deux des branches de l’économie, tandis que le titre d’emploi “enquêteur” peut désigner à la fois un chercheur scientifique et un enquêteur de police. De tels faits font généralement partie de la connaissance du domaine que les recruteurs utilisent au quotidien lorsqu’ils se plongent dans les CV et les offres d’emploi pour essayer de les comprendre et de les faire correspondre. Mais ce n’est pas nécessairement le cas des systèmes informatiques qui tentent de faire la même chose. Il en résulte généralement une performance sous-optimale des analyseurs de CV et d’offres d’emploi ainsi que des moteurs de recherche, car le manque de connaissance du domaine ne permet pas à ces systèmes de traiter des concepts du monde réel au lieu de chaînes de caractères, et de raisonner à leur sujet. Les modules logiciels de Textkernel, en revanche, ont accès à ces connaissances sous la forme de l’ontologie de Textkernel, un vaste graphe de connaissances qui définit et met en relation des concepts et des entités du domaine des ressources humaines et du recrutement, tels que les professions, les compétences, les qualifications, les établissements d’enseignement, les entreprises, etc. Grâce à l’ontologie, un agent (humain ou système informatique) peut répondre à des questions telles que les suivantes: – Quel type d’entité est un certain terme/mot-clé (une compétence, une profession, une entreprise, etc.)? – Quels sont les synonymes et/ou les variations orthographiques d’une certaine entité dans une certaine langue? – Une entité est-elle plus large ou plus étroite qu’une autre entité ? (par exemple, le développeur Java est-il une profession plus étroite que le développeur de logiciels ?) – Quelles sont les compétences les plus importantes pour une certaine profession ? – Quelles sont les qualifications importantes pour une certaine profession ? – Quels sont les emplois typiques qu’une personne ayant un certain titre de poste a précédemment occupés (parcours de carrière) ? Les “réponses” à ces questions, à savoir les connaissances du domaine, sont représentées et stockées dans l’ontologie selon un schéma unifié avec une sémantique claire et bien documentée. Chaque concept possède un identifiant unique (URI) et de riches informations linguistiques (synonymes et variations orthographiques) dans plusieurs langues. Ces informations permettent à nos parsers de mettre en correspondance les termes et les mots-clés, trouvés dans les CV et les offres d’emploi, avec les entités et les concepts avec une précision et une couverture très élevées. En outre, les concepts du même type sont organisés en hiérarchies taxonomiques où la signification d’un concept enfant est plus étroite que celle de son parent (par exemple, microéconomie plus étroite qu’économie). Les concepts de même type ou de type différent sont également liés de manière associative par des relations spécifiques au domaine (par exemple, les professions sont liées de manière associative aux compétences qu’elles requièrent le plus souvent sur le marché du travail). Les relations hiérarchiques et associatives permettent à nos systèmes de a) désambiguïser les termes ambigus lors de l’analyse des CV ou des offres d’emploi et b) de déterminer la similarité sémantique entre ces termes lors de la recherche ou de la mise en correspondance. Enfin, une caractéristique importante de l’ontologie de Textkernel est son interconnexion avec des graphes de connaissances et des taxonomies/vocabulaires externes, qu’ils soient liés au recrutement (par exemple, ISCO, ESCO, O*, etc.) ou à la recherche d’emploi (par exemple, le site Web de Textkernel), ISCO, ESCO, O*NET, ROME, etc.) que ceux à usage général (DBPedia, Eurovoc, etc.). En faisant correspondre nos propres concepts aux ressources de connaissances externes, nous facilitons a) le flux de connaissances de notre ontologie vers ces ressources et vice versa, et b) l’interopérabilité sémantique avec les systèmes qui utilisent déjà ces ressources. Ce dernier point est important car nombre de ces modèles sont des normes (au niveau international ou dans leurs pays respectifs) et sont donc largement utilisés par nos clients.

Construire et faire évoluer l’ontologie de Textkernel
La construction et la maintenance d’un vaste graphe de connaissances sur le domaine du recrutement constituent un défi de taille, non seulement parce que le domaine est très vaste, mais aussi parce qu’il est très hétérogène (différentes industries et secteurs d’activité, langues, marchés du travail, systèmes éducatifs, etc. Une approche entièrement manuelle (avec des experts humains définissant toutes les connaissances nécessaires) est trop coûteuse et ne peut pas être étendue, tandis qu’une approche entièrement automatique (avec des techniques d’exploration de données et d’apprentissage automatique utilisées pour extraire les connaissances du texte) peut souffrir d’une qualité médiocre. Pour relever ce défi, nous basons le développement de l’ontologie de Textkernel sur 3 principes:
Principe 1 : Définition du champ d’application et de la structure basée sur les besoins de l’entreprise et du système Le champ d’application et la structure/le schéma de l’ontologie de Textkernel ne sont pas déterminés arbitrairement mais ils sont guidés par les données réelles que nos systèmes doivent analyser et traiter, ainsi que par la façon dont ces systèmes (peuvent) utiliser l’ontologie afin de devenir plus efficaces. Cela signifie que chaque concept, attribut et relation défini dans l’ontologie doit non seulement être lié au(x) domaine(s) des données, mais aussi jouer un rôle concret dans la fonctionnalité de nos systèmes. Ainsi, par exemple, nous voulons disposer, pour tous nos concepts ontologiques, des termes lexicaux et des synonymes par lesquels ils peuvent apparaître dans les CV et les offres d’emploi, car cette connaissance est utilisée non seulement par nos parser mais aussi par nos modules search and match lorsqu’ils doivent développer une requête. Notre priorité est de disposer de ces informations linguistiques au moins en anglais, allemand, français et néerlandais, car ce sont les langues de la majorité des données que nous traitons. En même temps, nous utilisons des relations conceptuelles hiérarchiques et associatives pour a) parcourir et naviguer dans les données (p. ex, la taxonomie des professions dans Jobfeed), b) l’expansion des requêtes (par exemple, lorsque nous recherchons un expert en économie, nous pourrions également rechercher des experts dans les domaines plus étroits de la macroéconomie et de la microéconomie), et c) la désambiguïsation des entités (par exemple, une offre d’emploi demandant un enquêteur est une offre d’emploi), une offre d’emploi demandant un enquêteur pourrait être déterminée si elle se réfère à un chercheur scientifique ou à un enquêteur de police sur la base de la connaissance des compétences liées à ces deux professions).
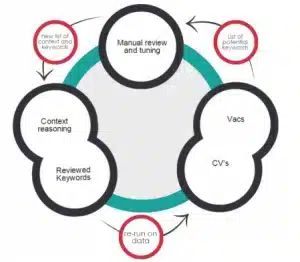
Principe 2 : Génération de contenu basée sur l’exploration d’ontologie guidée par les données Alors que le schéma de l’ontologie de Textkernel est construit d’une manière descendante, orientée métier et système (principe 1), son contenu (c.-à-d.., les concepts/entités réels et les valeurs d’attribut/de relation qu’il contient) est extrait et incorporé dans l’ontologie de manière (semi-)automatique à partir d’une variété de sources de données structurées et non structurées (exploration d’ontologie). Cette approche est nécessaire car la taille (plusieurs milliers d’entités et de concepts) et la dynamique du domaine du recrutement rendent une approche descendante, pilotée par des experts, infaisable en termes de coût et d’évolutivité. Pour mettre en œuvre cette approche, nous avons développé en interne des outils et des pipelines pertinents pour les différentes sous-tâches de l’exploration d’ontologie.
Certaines de ces sous-tâches sont :
T1 : Découvrir des entités (précédemment inconnues) d’un type donné (par exemple, découvrir que java est une compétence, que Textkernel est une entreprise ou que data scientist est une profession).
T2 : Extraire des synonymes, c’est-à-dire, étant donné un concept/entité de l’ontologie, découvrir des termes qui lui sont synonymes (par exemple, ingénieur logiciel – développeur de logiciels, société – entreprise, etc.).
T3 : Extraction de relations taxonomiques concept/entité, c’est-à-dire, étant donné un concept/entité de l’ontologie, découverte d’entités qui ont un sens plus large/plus étroit que lui (par exemple, java plus étroit que la programmation orientée objet, professionnel de l’informatique plus large que consultant en informatique, etc).
T4 : Extraction de relations binaires associatives, c’est-à-dire, étant donné une relation sémantique binaire associative, découvrir des paires d’entités qui sont liées par cette relation (par exemple, java est plus étroit que programmation objet, professionnel de l’informatique est plus large que consultant en informatique, etc, pour toutes ces tâches, nous développons et appliquons des algorithmes et des techniques d’apprentissage automatique et d’exploration de données de pointe. Mais surtout, nous nous attaquons à chaque tâche via un processus discipliné et structuré qui comprend les étapes suivantes: Étape 1 : Nous déterminons la tâche d’exploration exacte et la sémantique cible des informations à extraire. Étape 2 : Nous identifions et sélectionnons les données brutes qui sont les plus susceptibles de contenir les connaissances cibles (par exemple, les CV, les offres d’emploi, les journaux d’utilisateurs, etc). Cette étape est importante car les meilleures données pour une tâche donnée ne sont pas toujours toutes les données disponibles! Étape 3 : nous identifions les connaissances ontologiques existantes (internes ou externes) qui peuvent être utiles pour la tâche. Ces connaissances peuvent être utiles pour a) amorcer l’acquisition de données, b) créer des caractéristiques pour les algorithmes d’apprentissage automatique, c) raisonner sur les résultats des algorithmes d’exploration et d) mettre en œuvre des heuristiques. Etape 4 : Nous concevons/mettons en œuvre un pipeline d’exploration personnalisé qui est optimal pour la tâche et la sémantique spécifiques. Cela signifie qu’il faut sélectionner et orchestrer les algorithmes/outils les plus appropriés pour la tâche et, si nécessaire, ajouter des humains dans la boucle (voir principe 3) Étape 5 : Nous évaluons le résultat et le processus à la fois du point de vue algorithmique et du point de vue de la construction de l’ontologie. Cela signifie qu’en plus de mesurer le degré de précision et d’exhaustivité du processus (précision/rappel), nous déterminons également la rapidité et la rentabilité avec lesquelles nous obtenons une ontologie satisfaisante pour nos objectifs.
Principe 3 : L’homme dans la boucle pour l’assurance qualité et l’amélioration continue Même les meilleurs algorithmes d’exploration automatique d’ontologies sont sujets à un certain niveau d’imprécision qui, en fonction de la sous-tâche concrète, peut être significatif. C’est pourquoi, afin d’assurer la meilleure qualité possible pour l’ontologie de Textkernel, nous incorporons dans le processus d’exploration des jugements humains afin de traiter les cas où les algorithmes ne sont pas assez confiants ou fiables par rapport à leurs propres jugements. Ces jugements humains ne se contentent pas de compléter et d’évaluer la qualité des jugements algorithmiques, ils sont également transmis aux algorithmes pour les rendre plus “intelligents” et les aider à s’améliorer. De cette manière, la construction et l’évolution de l’ontologie deviennent un cercle vertueux capable de s’étendre.
Le diable se cache dans les détails
Dans les paragraphes précédents, j’ai donné un aperçu général de l’ontologie de Textkernel, de son utilisation au sein de l’entreprise et du processus que nous suivons pour son développement. Dans les articles suivants, je me plongerai dans les détails “diaboliques” de certaines des tâches les plus difficiles de ce processus, comme, par exemple, la découverte automatique de nouvelles compétences ou la détection de termes synonymes.
A propos de l’auteur
Panos Alexopoulos est le chef de l’équipe d’exploration d’ontologies chez Textkernel, responsable du développement, de la gestion et de l’évolution du graphe de connaissances de l’entreprise pour le domaine des ressources humaines et du recrutement. Né et élevé à Athènes, en Grèce, il est titulaire d’un doctorat en ingénierie des données et des connaissances de l’Université technique nationale d’Athènes, et il a plus de 10 ans d’expérience universitaire et industrielle combinée dans les domaines des technologies sémantiques et de l’ingénierie des connaissances. Lecteur vorace, il utilise son temps libre pour chasser les livres nouveaux et anciens, dans tous les endroits qu’il visite et dans toutes les langues qu’il peut (ou ne peut pas) comprendre.

