


A few years after Google announced that their knowledge graph allowed searching for things, not strings, knowledge graphs and ontologies have been gaining momentum in the world’s leading information organisations as a means to integrate, share and exploit data and knowledge that they need in order to stay competitive. But what exactly is a knowledge graph and what form and content does it have in the case of Textkernel? What approach is used to construct it in a scalable, time-effective way that keeps the quality high? And, most importantly, what benefits does it bring to the technology and, consequently, business and customers of Textkernel? These are the key questions Panos Alexopoulos, Lead Team Ontology Mining, will try to answer in this blog article.
By Panos Alexopoulos
Introducing Textkernel’s recruitment ontology
Data Scientist is a (very trendy) profession and hadoop is a skill that most data scientists need to have. Macroeconomics and microeconomics are both branches of economics while the job title “Investigator” may mean both a scientific researcher and a police investigator. Facts like these are typically part of the domain knowledge that recruiters use in their daily routines when they dive into CVs and vacancies trying to understand and match them. But not necessarily of computer systems that try to do the same.
This typically results in suboptimal performance of resume parser as well as search engines, as the lack of domain knowledge does not allow these systems to process real-world concepts instead of strings, and reason about them. Textkernel’s software modules, on the other hand, do have access to such knowledge in the form of Textkernel’s ontology, a large knowledge graph that defines and interrelates concepts and entities about the HR and recruiting domain, such as professions, skills, qualifications, educational institutes, companies etc. Via the ontology, an agent (human or computer system) can answer questions like the following:
– What kind of entity is a certain term/keyword (a skill, a profession, a company etc)?
– What are the synonyms and/or spelling variations of a certain entity in a certain language?
– Is an entity broader or narrower than another entity? (e.g., is java developer a narrower profession than software developer?)
– What are the most important skills for a certain profession?
– What qualifications are important for a certain profession?
– What are the typical jobs that someone with a certain job title has previously held (career path)?
The “answers” to these questions, namely the domain knowledge, are represented and stored within the ontology according to a unified schema with clear and well documented semantics. Each concept has a unique identifier (URI), and rich linguistic information (synonyms and spelling variations) in multiple languages. This information allows our resume parser to map terms and keywords, found in CVs and vacancies, to entities and concepts with a very high precision and coverage.
Moreover, concepts of the same type are organised in taxonomical hierarchies where the meaning of a child concept is narrower than the meaning of its parent (e.g., microeconomics narrower than economics). Concepts of the same or different type are also related in an associative way via domain-specific relations (e.g., professions are associatively related to the skills they mostly demand in the job market). Both hierarchical and associative relations enable our systems to a) disambiguate ambiguous terms when parsing CVs or jobs and b) determine the semantic similarity between these terms when searching or matching them.
Finally, an important feature of Textkernel’s ontology is its interlinking to external knowledge graphs and taxonomies/vocabularies, both recruiting-related ones (e.g., ISCO, ESCO, O*NET, ROME etc.) and general-purpose ones (e.g., DBPedia, Eurovoc). By having our own concepts mapped to the external knowledge resources we make easier a) the flow of knowledge from our ontology to these resources and vice versa, and b) the semantic interoperability with systems that already use these resources. The latter is important as many of these models are standards (either internationally or in their respective countries) and therefore widely used by our clients.

Building and evolving Textkernel’s ontology
Constructing and maintaining a large knowledge graph about the recruitment domain is a big challenge not only because the domain is quite large but also because it is very heterogeneous (different industries and business areas, languages, labour markets, educational systems etc.) and changes in a very fast pace. A fully manual approach (with human experts defining all necessary knowledge) is too costly and cannot scale, while a fully automatic one (with data mining and machine learning techniques being used for extracting the knowledge from text) may suffer from low quality. To deal with this challenge we base the development of Textkernel’s ontology upon 3 principles:
Principle 1: Scope and structure definition based on business and system needs scope and structure/schema of Textkernel’s ontology is not determined arbitrarily but it is driven by the actual data that our systems need to analyse and process, as well as the way these systems (can) use the ontology in order to become more effective. This means that every concept, attribute and relation defined in the ontology needs not only to be related to the domain(s) of the data, but also to serve some concrete role in our systems’ functionality.
Thus, for example, we do want to have, for all our ontology concepts, lexical terms and synonyms by which they may appear in CVs and vacancies, as this knowledge is used not only by our resume parser but also by our search and match modules when they need to do query expansion. And our priority is to have this linguistic information available in at least English, German, French and Dutch, as these are the languages of the majority of the data we process.
At the same time we utilise both hierarchical and associative concept relations for a) browsing and navigation of data (e.g., the profession taxonomy in Jobfeed), b) query expansion (e.g., when looking for an economics expert, we could look also for experts in the narrower areas of macroeconomics and microeconomics), and c) for entity disambiguation (e.g., a vacancy requesting an investigator could be determined whether it refers to a scientific researcher or a police investigator based on the knowledge of the skills these two professions are related to).
Principle 2: Content generation based on data-driven ontology mining
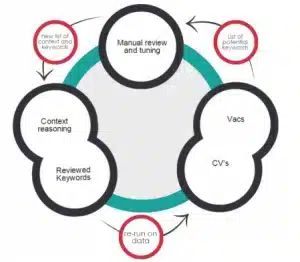
While the schema of Textkernel’s ontology is built in a top-down, business and system-driven way (principle 1), its content (i.e., the actual concepts/entities and attribute/relation values it contains) is extracted and incorporated into the ontology in a (semi-)automatic way from a variety of structured and unstructured data sources (ontology mining). This approach is necessary as the size (several thousands of entities and concepts) and dynamics of the recruitment domain make a top-down, expert-driven approach infeasible in terms of cost and scalability.
To implement this approach, we have been developing in-house relevant tools and pipelines for different sub-tasks of ontology mining. Some of these sub-tasks are:
T1: Discovering (previously unknown) entities of a given type (e.g. discovering that java is a skill, Textkernel is a company, or data scientist is a profession).
T2: Mining synonyms, i.e., given an ontology concept/entity, discover terms that are synonymous to it (e.g., software engineer – software developer, company – enterprise, etc).
T3: Mining concept/entity taxonomical relations, i.e., given an ontology concept/entity, discover entities that have a broader/narrower meaning than it (e.g., java narrower than object oriented programming, IT professional broader than IT consultant, etc).
T4: Mining associative binary relations, i.e., given an associative binary semantic relation, discover pairs of entities that are related through it (e.g., data scientist needs to know about hadoop, Textkernel has headquarters in Amsterdam, University of Amsterdam provides course in artificial intelligence, etc.).
For all these tasks, we develop and apply state-of-the-art machine learning and data mining algorithms and techniques (see for example Maarten’s blogpost on deep learning for job normalization) More importantly, though, we tackle each task via a disciplined and structured process that included the following steps:
Step 1: We determine the exact mining task and the target semantics of the information to be mined.
Step 2: We identify and select the raw data that are most likely to contain the target knowledge (e.g. CVs, vacancies, user logs etc). This is important as the best data for a given task are not always all the available data!
Step 3: We identify existing ontological knowledge (internal or external) that can be useful to the task. This knowledge can be useful for a) bootstrapping data acquisition, b) feature creation for machine learning algorithms, c) reasoning on the output of the mining algorithm(s), and d) implementing heuristics.
Step 4: We design/implement a custom mining pipeline that is optimal for the specific task and semantics. This means selecting and orchestrating the most appropriate algorithms/tools for the task and, if necessary, add humans in the loop (see principle 3)
Step 5: We evaluate the outcome and process both from an algorithmic and ontology construction perspective. This means that in addition to measuring how accurate and complete is the process (precision/recall), we also determine how fast and cost-effectively we get a satisfactory ontology for our goals.
Principle 3: Human-in-the-loop for quality assurance and continuous improvement. Even the best automatic ontology mining algorithms are prone to some level of imprecision which, depending on the concrete sub-task, can be significant. That’s why, to ensure the highest quality possible for Textkernel’s ontology, we incorporate in the mining process human judgments so as to deal with cases where the algorithms are not confident or reliable enough with respect to their own judgments. These human judgments do not only complement and assess the quality of the algorithmic ones, but they are also fed back to the algorithms to make them “smarter” and help them improve. In that way, the construction and evolution of the ontology becomes a virtuous circle that is able to scale.
The devil is in the details
In the previous paragraphs I have given a high-level overview of Textkernel’s ontology, its usage within the company, and the process we follow for its development. In subsequent posts I will dive into the “devilish” details of some of the highly challenging tasks involved in the latter process like, for example, the automatic discovery of new skills or the detection of synonym terms.
About the author
Panos Alexopoulos is the Lead of the Ontology Mining Team at Textkernel, being responsible for the development, management and evolution of the company’s knowledge graph for the HR and Recruiting domain. Born and raised in Athens, Greece, he holds a PhD in Data and Knowledge Engineering from National Technical University of Athens, and he has more than 10 years of combined academic and industrial experience in the areas of semantic technologies and knowledge engineering. Being a voracious reader, he uses his spare time to hunt new and old books, in every place he visits and in every language he can (or cannot) understand.

