

A Java programmer does the same as a Java developer does the same as a Java software engineer does the same as a Java ninja (although one of them might be faster, better, stronger than the others). So when an applicant looks for a job as a Java developer they will also be interested in seeing job postings that only list “Java programmer”. Also recruiters want to find all java developers on the market and not just the ones using this exact job title.
This is the challenge behind job title normalization, an essential component of Textkernel’s technology. Accurate job title normalization is an indispensable part of our Source & Match products. In this blog post Maarten Versteegh, Senior NLP Research Engineer at Textkernel, details a piece of research we have done to improve job title normalization.
Deep research
At Textkernel, we are constantly pushing the state of the art with our technology. Therefore, we are always evaluating new ideas and techniques to make our products better. Sometimes these ideas are incremental improvements on our existing technology. In those cases our users will see a percent better accuracy here or there, or the eradication of a particular type of error our system makes. In other cases we take a big step back from our systems and ask ourselves how a different approach might fare.
This is the case with our research into using deep learning for job title normalization. Inspired by recent advances in machine learning, in particular by the successes that recurrent neural networks have had in the field of natural language processing, we decided to initiate an investigation into using these networks for the task of job title normalization. Our efforts paid off and our research was presented at the 1st Representation Learning for NLP workshop, hosted at ACL2016 in Berlin.
Job title normalization
Many job titles can be written in different ways. To use a different example than the “Java developer” mentioned above, the venerable recruiter may also be called “talent sourcer” or “talent acquisition manager”. These are different wordings, but mean the same thing. This phenomenon is not limited to these two examples. Almost all job titles have variants depending on company culture, industry or the whim of the talent sourcer writing the vacancy.
The common way for computers to represent text is as a sequence of individual letters, so the word “recruiter” is represented as [‘r’, ‘e’, ‘c’, ‘r’, ‘u’, ‘i’, ‘t’, ‘e’, ‘r’]. Therefore, the natural way for a computer program to determine whether two job titles are the same, is to compare the two sequences that represent the job title based on their letters. In this sense the sequence [‘r’, ‘e’, ‘c’, ‘r’, ‘u’, ‘i’, ‘t’, ‘e’, ‘r’] is not the same as the sequence [‘t’, ‘a’, ‘l’, ‘e’, ‘n’, ‘t’, ‘ ‘, ‘s’, ‘o’, ‘u’, ‘r’, ‘c’, ‘e’, ‘r’]. So under this interpretation of equality, it should be clear that the answer to the question whether “recruiter” is the same as “talent sourcer”, is a resounding “No!”. Moreover, this way of defining equality between texts cannot even handle simple spelling variants or errors. While we as humans can clearly tell that “recruiter” and “recriuter” is probably meant to be the same thing, this is harder for computers. We need something smarter than equality based on the letter sequence if we want to handle these cases.
Any system that intends to process these job titles therefore needs to understand that some sequences of characters that look different from each other are in fact synonymous. Therefore, a good job title normalizer needs to consider the meaning of the character sequences, not just their surface form.
In some cases this meaning can manifest as the combination of the meanings of individual words or phrases. Without knowing anything about the (entirely fictional) industry of crocodile rubber ducking, for example, we would still guess that a “Crocodile rubber ducking coordinator” is likely the same as a “Crocodile rubber ducking manager”. We know this, because we know that coordinator and manager are similar roles and we know that those words can combine with words indicating an industry (like crocodile rubber ducking) to denote someone who takes a leading position in that industry, e.g. IT manager. So sometimes it is the case that not the entire job title has a synonym, but a part of it does. A good job title normalizer exploits this information to find the correct job.
But in fact, synonymy is not the only aspect that the system needs to consider. Often, job postings do not simply list the job title, but add in some extra information. For example, it is not uncommon to find job postings on the internet along the lines of “Looking for Java/J2EE developers URGENT!!!”. For humans it is easy to understand that the intended job title is something like “Java developer”, but for computers this is far from trivial. So a good system for job title normalization also needs to be able to extract the intent of the job poster from the listing and ignore those words that do not directly refer to a job title.
Lastly, the job title normalizer should not get confused by spelling errors. The ubiquity of spelling checkers notwithstanding, typos often make their way into job listings. Relatedly, a good job title normaliser should be able to handle small spelling variants, like the differences between British and American English, with ease, otherwise it will not be of use for the labour cq. labor market.
This then is the shortlist of requirements for a good job title normalizer:
1. it should understand synonyms
2. it should ignore words that do not refer to job titles
3. it should be able to handle typos and spelling differences.
Machine learning for job titles
We could attempt to meet these requirements with a system that works with handwritten rules or that only looks at the surface form of the character sequences, but that kind of system would become very complicated very quickly and would likely not capture the semantic properties that we are looking for. Instead, we turned to a different approach: deep learning.
Deep learning is a recent development in machine learning that has shown enormous successes in applications from speech and visual recognition, machine translation and automatic question answering. While the details are beyond the scope of this blog post, the ideas behind deep learning are actually relatively simple. In traditional machine learning approaches, a lot of manual effort is spent in constructing so-called features. Features are measurable properties of data that can be used to make predictions. As an example, features for a job title normalizer may be properties like “contains the word ‘manager’”, which would be true for “talent acquisition manager”, but false for “recruiter”. Features that describe combinations of characters are often useful for text processing. So the feature “contains the character sequence ‘acq’” would be true for “talent acquisition manager” but false for “recruiter”.
These kinds of features are easy to understand, but it should be clear that there are a lot possibilities for constructing them. Which words do we look for in the text? Which character combinations are important? Or should we look at word combinations? Maybe some kind of semantic representation for the words would be good? The choice of features can have a strong impact on the accuracy of the predictions that a machine learning model can make. Picking the wrong features for a job title normalizer will hurt its performance.
Deep learning for job titles
This is where deep learning comes in. Deep learning is a family of techniques that automatically learns the correct features by transforming the data with a large number of simple functions. These simple functions are optimised by the system to best satisfy some criterion, for example class prediction accuracy. In order to do this we need lots of data and a smart criterion to optimise against.
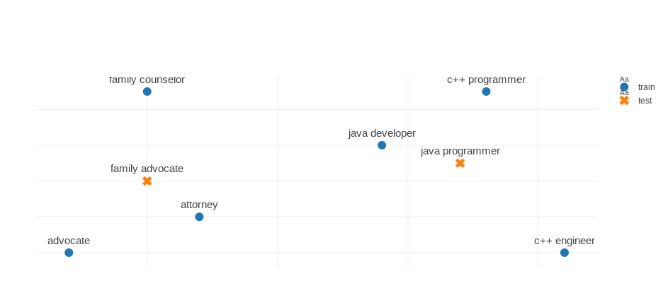
The system we built aims to learn the structure of a space in which similar job titles lie close together and dissimilar job titles are far apart. Figure 1 shows an example of the kind of space we are interested in learning.
See Figure 1. Toy example of a good representation space. The blue examples are seen during training, the orange job titles were not observed before. Similar job titles are close together and the unobserved job titles are close to related job titles. Thanks to Paul Neculoiu for providing this figure.
To learn this representation, we make use of information about pairs of job titles. We select a large amount of pairs of job titles and associate with each of them a judgment that says whether they are similar or dissimilar. The table below shows some examples of pairs of job titles. To train our model, we gathered millions of such pairs and fed them to our model.
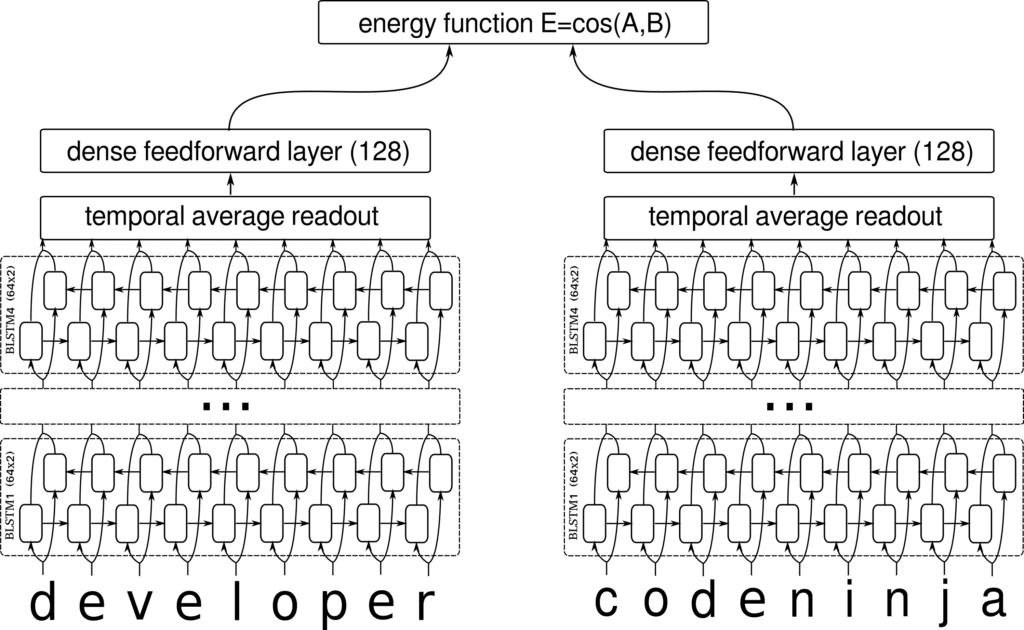
The model we designed builds on the so-called Siamese Neural Network, which aims to process pairs of samples and learn a useful representation of individual samples by projecting them into a space which satisfies some criteria. In our case, the criterion of the space is the now familiar mantra that similar job titles should be close together and dissimilar job titles should be far apart. The closeness in this space is controlled by an energy function, which is used to determine how well any particular configuration satisfies this criterion. Figure 2 shows an overview of the network. For the precise details of how the network is constructed and trained.
When the system has learned to put similar job titles close together and dissimilar ones far apart, it turns out we have everything we wanted for our normalizer: it understands synonyms, it ignores words that do not refer to job titles and it can handle typos and spelling differences.
This result is yet another indication that deep learning is an incredibly powerful set of techniques for machine intelligence. We are investigating in which ways we can further optimise the rest of our semantic recruitment software. Stay tuned!

{kind=link}